本文是CVPR 2022入选论文《Instance-Aware Dynamic Neural Network Quantization》的解读。该论文由北京大学马思伟课题组完成,基于数据集中样本的多样性,提出了针对不同样本分配不同计算资源的量化方法。 该方法设计了一个轻量级的比特控制器,可以与主网络进行联合训练。实验证明,该论文所提出的方法可以与主流的量化方法结合,在相同的计算量条件下可以实现更高的准确率。
成果速览 | CVPR2022 样本自适应量化方法
作者:刘振华
发表时间:2022-05-06
来源:PKUVCL(微信公众号)
一、引言
量化是一种常用且有效的降低神经网络存储和计算量的方法,然而当量化比特宽度较低时,会带来较大的性能损失。因此如何提升量化模型的准确率以及挖掘量化模型的压缩潜能是一个值得研究的课题。在传统的量化方法中,数据集中样本的多样性通常是一个被忽略的因素。 事实上,如何有效地处理难易样本是计算机视觉中一个普遍存在的问题,即使用深度神经网络处理不同的样本所需的资源往往是不同的。例如,一个训练好的网络很容易可以识别只包含一只狗的图像,但识别一张街景中模糊的自行车是比较困难的。根据这种思想, Wu等[1]提出在推理过程中动态选择深层网络的网络层,来达到减少总计算量的目的;Cheng等[2]提出单个网络结构可能不足以处理一个复杂的数据集,因此他们根据样本的不同来搜索不同的网络结构。然而,基于样本感知的动态策略还没有被应用到深度神经网络的量化方法中。
根据以上分析,本文提出了一种样本自适应的量化神经网络。它会根据不同的输入样本动态地分配量化神经网络的比特宽度。具体而言,给定一个网络结构,它会生成大量不同量化方案的隐藏子网络。在推理过程中,难以被准确识别的图像将被分配一个较大的子网络,反之亦然。 本文设计了一个比特控制器,用于预测给定样本的每一层的权重值和激活值(即输出特征)的最佳比特宽度。比特控制器采用了非常小的网络结构,这样可以避免对量化网络增加明显的内存和计算资源消耗。然后,本方法采用了计算复杂度的正则化函数来降低优化难度, 从而有效地获得具有期望计算量约束的量化网络。为了获得更好的性能,样本自适应的量化神经网络与比特控制器以端到端的方式一起进行训练。
二、方法简介
通常来说,深度神经网络在训练和推理过程中都是使用的浮点数,也就是说权重值和激活值都是使用32比特来存储的。神经网络量化方法通过将这些浮点的权重值和激活值用更低比特的数表示来减低神经网络的计算和存储需求。 为了量化权重值和激活值,这些浮点数需要使用一些有限的数来表示。量化方法的函数可以如下表示:

其中z表示输入的权重值或者激活值。
对于量化步长的选择,经常使用的一种方法是均匀量化,也就是说量化范围被均匀分割,即
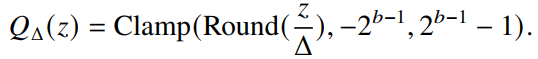
其中
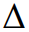 是均匀量化的步长,而Clamp和Round分别表示截断和四舍五入函数。
是均匀量化的步长,而Clamp和Round分别表示截断和四舍五入函数。
在以往的量化方法中,每个网络层的量化比特宽度对于所有输入都是相同的,这没有考虑到输入样本的多样性和复杂性。为了更合理地分配计算资源,本文提出根据输入的样本动态调整分配给每个网络层的比特宽度。 样本自适应量化的目的是为每个样本分配最合适的权重值和激活值比特以节省存储和计算资源。假设有K个比特宽度的选择,那么样本自适应量化可以用如下公式表示:
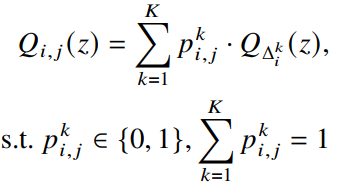
其中
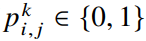 表示对于第j个样本在第i层是否选择第k个比特宽度。
表示对于第j个样本在第i层是否选择第k个比特宽度。
这样,对于第j个样本在第i个网络层的样本自适应量化可以表示为:
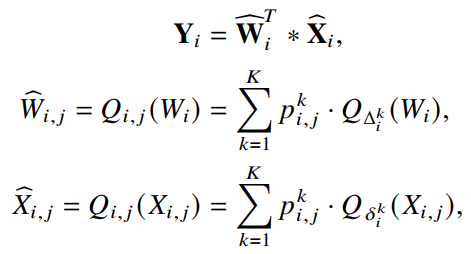
通过上述公式,样本自适应量化卷积可以通过给定一个输入来决定不同层的比特宽度实现,可以充分挖掘深度神经网络的量化潜能。
 图1 样本自适应量化方法整体框架
图1 样本自适应量化方法整体框架
本文所提出的样本自适应量化方法的基本框架如图1所示。给定一张输入图像,方法的目标是找到一个量化网络性能和计算复杂度之间的最佳平衡。 因此,量化网络可以在受限计算资源的情况下发挥更好的性能。然而,这个问题是不能直接进行优化的,因为比特宽度选择对于每个网络层都不是固定的,而是与输入图像相关的。为了解决这个难题, 本文使用了一个比特控制器来根据输入图像的复杂程度来动态预测每个网络层权重值和激活值的理想比特宽度。在实际过程中,比特控制器的输入是一幅图像,输出是包含预测的比特选择的向量, 这个向量代表着这幅图像在每一个网络层中选择某个比特宽度的概率。
为了防止增加网络整体的存储和计算量,本文设计了一个轻量级的比特控制器。具体而言,比特控制器是由主网络中的前几个网络层和一个多层感知机组成的,而这个多层感知机只包含两层的全连接层。 通过这种方式,本文提出的样本自适应量化方法可以在增加极少的计算量情况下根据样本的复杂度预测每个网络层的量化比特宽度。此外,比特控制器和主网络是可以进行共同训练的,也就是说它们可以进行联合优化。
假设比特控制器的输出的权重和激活值的量化比特宽度的概率值为
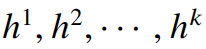 ,那么可以根据这些概率值生成最终的量化比特选择,即:
,那么可以根据这些概率值生成最终的量化比特选择,即:

如图2所示,在训练和推理过程中,只有一个比特宽度会被选择,为了使取极值操作变得可导,本文在训练过程中使用了Gumbel-Softmax函数。给定一个输入样本,在量化网络的前向过程中, 获得某一层的比特宽度之后,样本自适应量化方法会据此来量化对应层的权重值和激活值:
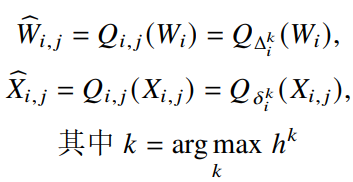
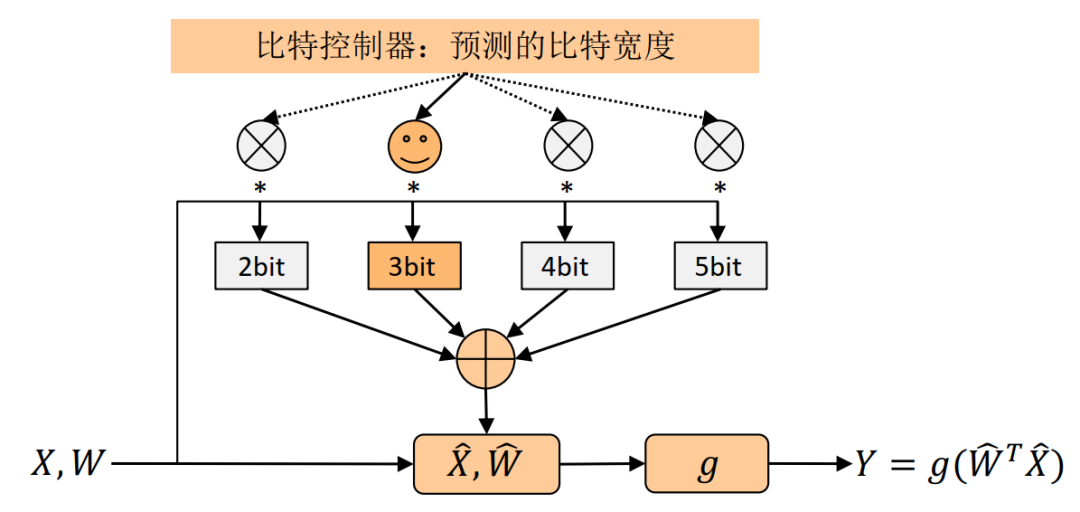 图2 样本自适应量化方法单个网络层的示意图
图2 样本自适应量化方法单个网络层的示意图
三、实验结果
本文主要在两个数据集上测试所提出方法的性能和可行性,分别为CIFAR-10和ImageNet数据集。CIFAR-10数据集包括5万张训练图像和1万张测试图像,共被分为了10类。 ImageNet数据集包括120万张训练图像和5万张验证集图像,它们被分为了100类。
表1展示了本文所提方法在CIFAR-10数据集上使用ResNet20模型的量化性能,在相似的比特计算量下,本文所提的方法的平均Top-1准确率比DoReFa和PACT方法分别高了0.43%和0.26%。 在相似或者更高Top-1准确率下可以节省35~40%的计算量。
表1 样本自适应量化方法在CIFAR-10数据集上使用ResNet20模型的量化性能

表2展示了所提方法在ImageNet数据集上使用ResNet-50模型的量化性能。样本自适应量化方法在相似精度情况下,节省了36%的计算量。这些结果充分说明了对于大数据集上的实用性以及鲁棒性。
表2 样本自适应量化方法在ImageNet数据集上使用ResNet50模型的量化性能
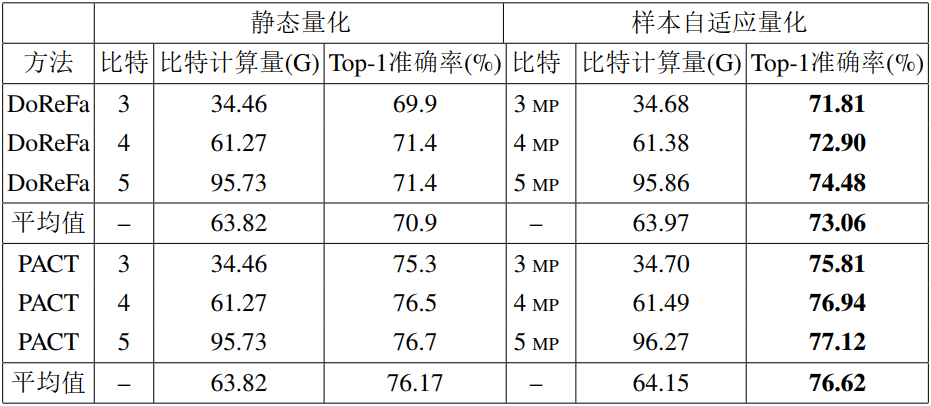
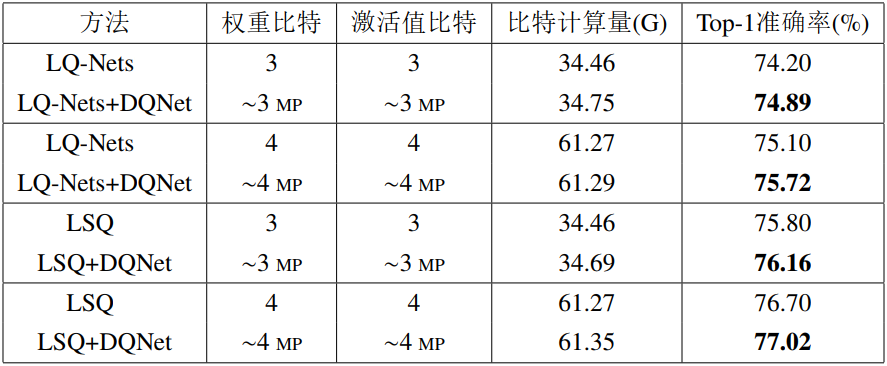
表3展示了使用ResNet-50模型在LQ-Nets和LSQ方法上使用样本自适应量化方法的性能。LSQ方法是性能更好的量化方法,样本自适应量化方法可以进一步提升它的性能, 分别在3比特和4比特条件下可以获得0.36%和0.32%的Top-1准确率提升,进一步说明了本文所提方法的有效性。
表3 在LQ-Nets和LSQ方法基础上使用样本自适应量化方法的量化性能
更多方法及实验细节详见原论文。
参考文献
[1]Zuxuan Wu, Tushar Nagarajan, Abhishek Kumar et al. “BlockDrop: Dynamic Inference Paths in Residual Networks.”In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition.2018:8817-8826.
[2]An-Chieh Cheng, Chieh Hubert Lin, Da-Cheng Juan et al. “InstaNAS: Instance-Aware Neural Architecture Search.”In Proceedings of the AAAI Conferenceon Artificial Intelligence.2020:3577-3584.